

Компания — российский федеральный ритейлер, чья сеть супермаркетов по всей стране значительно выросла в последние годы за счет присоединения ряда региональных торговых сетей.
Проблема: разрозненные архивы и отсутствие единого учета
Рост компании, в том числе за счёт поглощения других сетей, привёл к накоплению значительных объёмов документов разного формата.
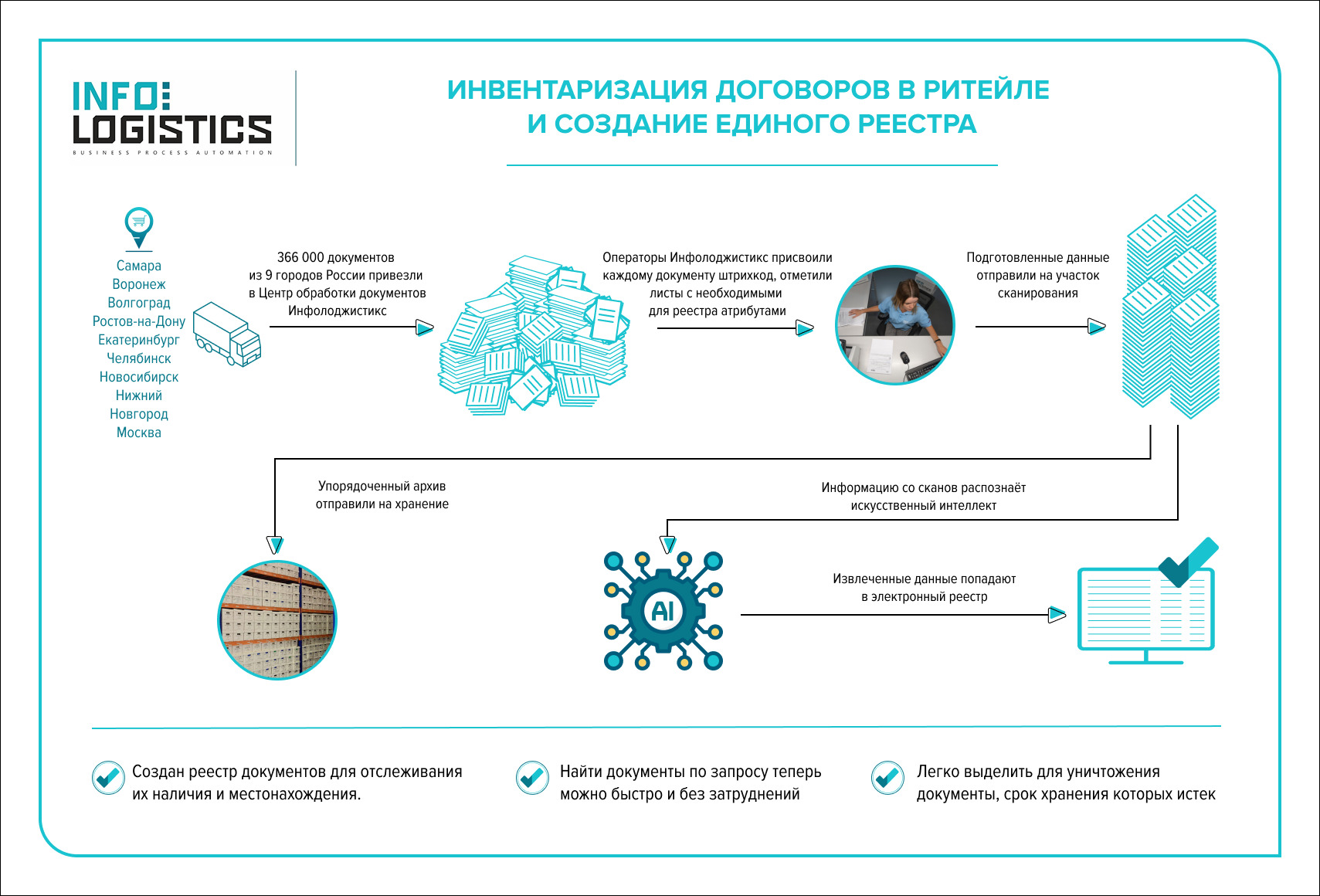
Проблема заключалась в том, что в каждой приобретённой сети учёт и хранение документов были организованы по-своему. К тому же, а рхивы находились в разрозненных филиалах по всей стране: Самара, Ростов-на-Дону, Воронеж, Челябинск, Новосибирск, Екатеринбург, Москва, Волгоград и Нижний Новгород. В результате поиск нужного документа в постоянно растущем массиве становился сложной задачей: не было ясности, где хранится тот или иной документ и сохранился ли его оригинал в компании.
Для систематизации документов было решено провести инвентаризацию архива, которая позволила бы решить три ключевые задачи:
- Получить точное представление о составе документов и их физическом местонахождении.
- Оперативно находить и предоставлять необходимые документы по запросу.
- Своевременно уничтожать документы с истёкшим сроком хранения в соответствии с требованиями политики информационной безопасности.
Цель проекта
В ходе полной инвентаризации договоров нужно было создать единый реестр с одинаковым набором данных для документов из всех филиалов. Для этого из каждого документа требовалось извлечь ключевые данные: тип, номер, дату заключения, контрагента, адрес объекта, ИНН и наименования юридических лиц подразделений.
Кроме этих атрибутов нужны были и неструктурированные данные, которые требовали дополнительного анализа и распознания:
Неявные атрибуты. Некоторые сведения, такие как дата расторжения, указывались в договоре в виде формулировок. Например, условие «3 года с даты заключения» или штамп «считать дату расторжения другой» требовали проведения ручных расчетов и проверки. Эта кропотливая работа требовала повышенной внимательности, особенно с учетом того, что срок действия отдельных документов распространяется до 2057 года.
Рукописное оформление. Часть документов содержала рукописные пометки, штампы с корректировками или реквизиты, оформленные не по стандартному шаблону — это затрудняло их обработку.
Как мы построили процесс с применением ИИ
Работу по инвентаризации договоров мы выстроили по конвейерному принципу, разделив её на этапы. На каждом из них документы тщательно проверяли вручную, чтобы обеспечить точность и полноту реестра.
Шаг 1. Подготовка и разметка бумажных документов
Для быстрого поиска бумажных оригиналов в архиве операторы присвоили каждому документу уникальный штрихкод и занесли его в реестр. Кроме того, мы заранее разметили документы для упрощенного извлечения данных на следующих этапах.
Шаг 2. Выборочное сканирование
Размеченные документы отправили на сканирование. Поскольку полный электронный архив не требовался, мы оцифровывали только информацию, необходимую для реестра. Это дало возможность в дальнейшем автоматически извлекать данные из скан-копий и сократило сроки выполнения работы.
Шаг 3. Распознавание и верификация данных
Для распознавания данных с оцифрованных документов и анализа документов для атрибутирования неявных параметров мы подключили искусственный интеллект. На его долю пришлось около 90% обработки.
Искусственный интеллект применялся в сложных случаях, где требовалось, например:
- проанализировать смысл текста — например, чтобы определить предмет договора, который явно не указан;
- провести расчеты — например, вычислить дату расторжения договора на основе даты его заключения и т.д
В процессе верификации данных оказалось, что такой подход обеспечил высокую корректность извлечения как прямых атрибутов, так и тех, которые требовали вычисления. Это дало возможность перейти на выборочную проверку результатов вместо сплошного контроля и ещё ускорить процесс.
Комбинация предварительной разметки, точечного сканирования и выборочного контроля свела к минимуму риск ошибок и позволила выполнить работу в сжатые сроки.
Результат
В рамках проекта мы провели полную инвентаризацию договоров и создали централизованный реестр. В него внесли унифицированные данные по всем документам из 9 регионов присутствия компании. Всего за полгода было обработано 366 000 документов, и проект продолжается с новыми документами.
В цифровом реестре теперь можно быстро найти любой договор и увидеть местонахождение его бумажного оригинала — такой подход помогает выстроить учет физических оригиналов документов и контролировать работу с архивом.
Единый реестр со всеми данными позволяет легко выявлять документы, у которых истёк срок хранения, для их дальнейшего уничтожения.












